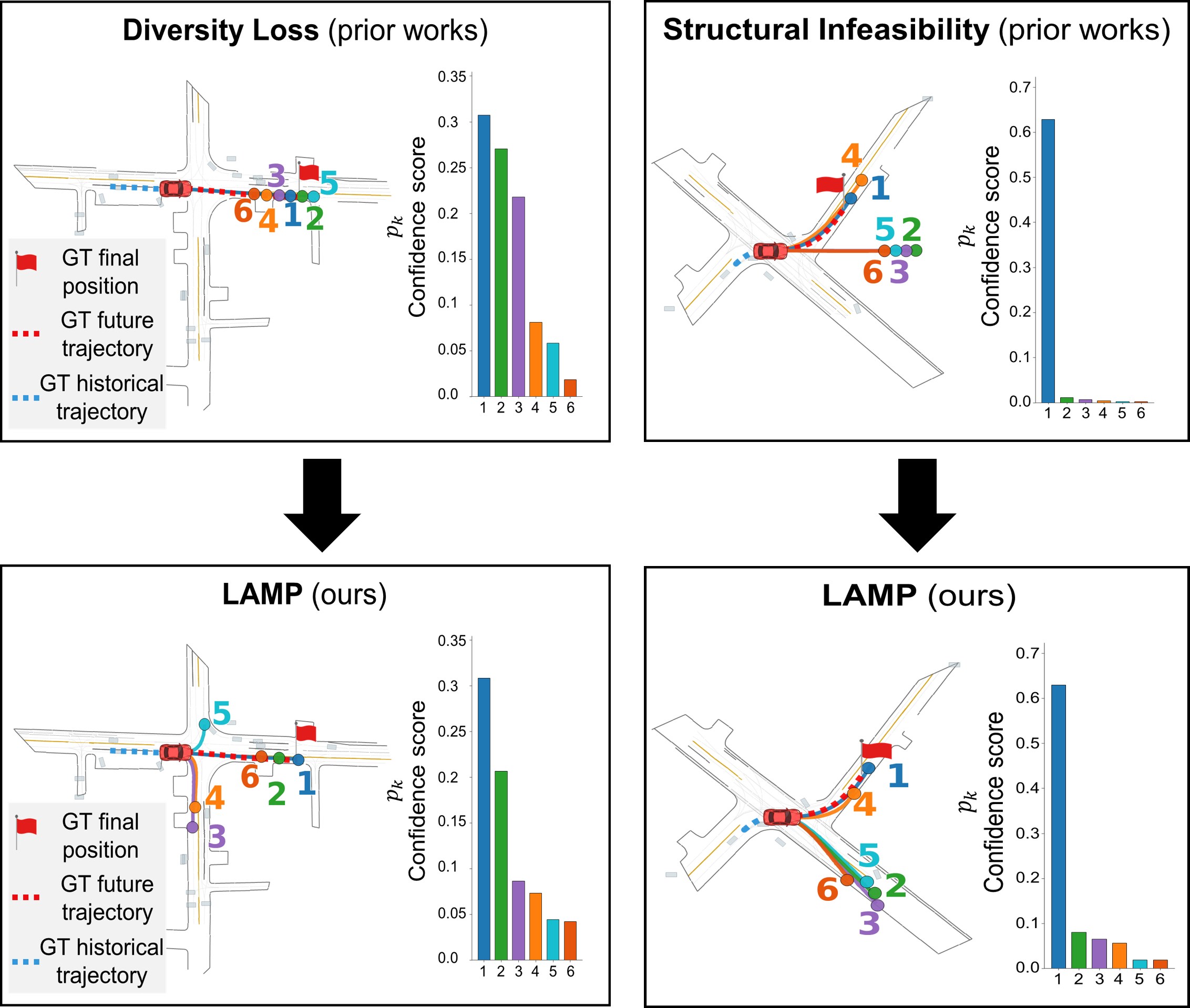
Motivation
Multimodal motion forecasting must be accurate, feasible, and diverse to support safe planning. However, existing predictors rely on scene-agnostic intention priors (anchors, target points) and training objectives that prioritize the most-probable ground-truth mode. As a result, lower-probability modes often violate lane topology or traffic rules, producing off-road or unreachable trajectories that are unreliable for downstream planners.
Approach
We propose LAMP (Lane-Aligned Motion Primitives), a topology-aware motion forecasting framework that improves the reliability of multimodal prediction sets by combining structured motion primitives with feasibility-aware intention selection.
Method
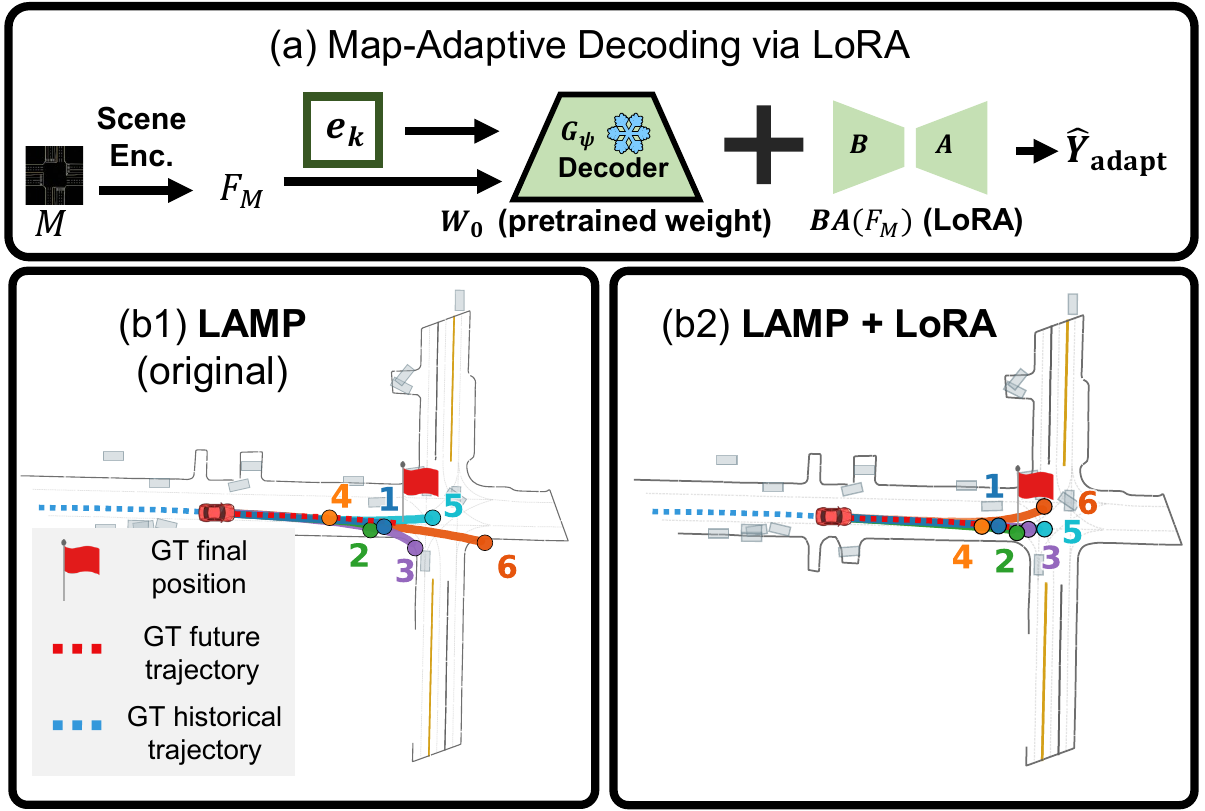
LAMP builds on two design principles. (i) We learn a discrete codebook of shape-aware motion primitives via an NSVQ-based VQ-VAE, capturing the full spatiotemporal dynamics of driving intentions beyond endpoint-based priors. (ii) We use HD-map reachable-lane sets as a soft teacher distribution to train a lane-topology-guided intention selector that filters infeasible intention queries before they enter the Transformer decoder.
Results
On the Argoverse 2 motion forecasting benchmark, LAMP matches strong baselines on displacement accuracy while substantially improving feasibility — particularly the planner-relevant traffic-rule metric FR (0.665 → 0.774 vs. MTR) — and diversity (DwF 7.811 → 12.559 vs. MTR). This combination of diverse, lane-compliant hypotheses provides more reliable multimodal prediction sets for downstream planning.